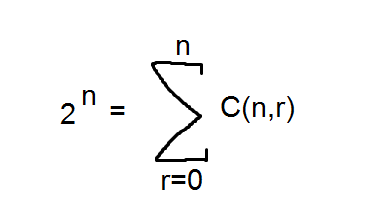Let's use an example: A guy has 7 dollars and he wants to spend all of it and he goes to a vending machine where each drink (due to some savvy and possibly illegal price fixing) costs 1 dollar each. The guy can choose from water, coke, pepsi and OJ and yes that's canned OJ which will one day hopefully become a reality. So he's got four categories to choose from and seven 'slots' effectively. The problem here is that unlike previous combinatorics problems where you could only use each element once, we can say here that there is an infinite supply of each category (or there are at least seven of each drink in the vending machine; price fixing or no price fixing there is no economical mechanism to create an infinite vending machine). So how can we go about looking at this problem in a way so that there are no repetitions and hence we can use our handy C(n,r) formula?
We can start by just using a tally of how many of each drink the guy can buy:
Water Coke Pepsi OJ
1 11 111 1 = 7
1111 11 1 = 7
111 1 1 11 = 7
Listing all of these states might take some time, but even if we listed all of them, it's not clear how we can use this layout to end up with something along the lines of C(n,r). How about we represent each of these different states as a bit string, using 0's to represent the transition from one category to another:
Water Coke Pepsi OJ
1 0 11 0 111 0 1 or 1011011101
0 1111 0 11 0 1 or 0111101101
111 0 1 0 1 0 11 or 1110101011
each of these bitstrings will end up with 10 digits; that's 7 for the seven slots we have plus an extra three for each transition (and the #transitions = #categories-1). So if our problem involves 's' slots and 'c' categories, the number of digits we'll have will always be s+c-1.
Should we stop here and say 'well clearly there are 2^10 = 1024 numbers represented by 10 bits so that's the number of combinations we have'? Although the bitstrings are good representations of the problem and every state has a unique representation, you're never going to see a bitstring like 1000000111 because we can only have 3 0's and thus we can only have 7 1's, so we know the number we'll end up with will be less than 1024.
So what can we do? How about we give each place in the bitstring an alphabetical index:
a b c d e f g h i j
1 0 1 1 1 0 1 1 0 1
0 1 1 1 1 0 1 1 0 1
1 1 1 0 1 0 1 0 1 1
Now we can use another way of representing the different states: just find out the positions that the 0's are in. If you came up to me and told me there were ten digits, indexed with letters, and the zeros were in the places {b,f,i} like in the first state, I'd be able to work out that there must be 1 water purchased, 3 cokes, 2 pepsi's and 1 can of delicious OJ. So clearly just using a set of the three positions that the zeros belong to is enough to describe one state:
a b c d e f g h i j
1 0 1 1 1 0 1 1 0 1 --> {b,f,i}
0 1 1 1 1 0 1 1 0 1 --> {a,f,i}
1 1 1 0 1 0 1 0 1 1 --> {d,f,h}
Now we just need to ask how many ways there are of making a set of 3 elements using our 10 letters? Well that's something we can apply the C(n,r) formula to: we have 10 letters and we need to choose 3? That's just C(10,3) = 120. So our guy can walk away with one of 120 possible combinations of drinks. So where do the 10 and 3 come from? As I said above, the 10 is the number of digits in the bitstring which will be the original number of slots (7) plus the number of transitions (#categories-1 = 4-1 = 3). The 3 in C(10,3) is just the number of transitions.
So given a problem where you need to fill s slots with c categories, you can use C(s+c-1,c-1). You may be thinking 'what about that symmetrical property where C(n,r) = C(n,n-r). Well in this case n = s+c-1 and r = c-1 so that translates to C(s+c-1,(s+c-1)-(c-1)) which is C(s+c-1,s). What does this mean? Well it means if you tried to find all the ways of putting those 10 letters into a set with 7 slots (one slot for each '1' in the bitstring) you'd get the same number of combinations. Just like above, we can construct a set using all the letters which don't have a corresponding '0' (i.e. they've got a '1'):
a b c d e f g h i j
1 0 1 1 1 0 1 1 0 1 --> {a,c,d,e,g,h,j}
0 1 1 1 1 0 1 1 0 1 --> {b,c,d,e,g,h,j}
1 1 1 0 1 0 1 0 1 1 --> {a,b,c,e,g,i,j}
So each of these sets will also tell me how many of each drink the guy chose e.g. looking at the first set, the 'a' says he got 1 water, then there's a jump to c meaning now he's getting cokes so he gets 3 cokes then there's a jump to g meaning now he's getting pepsi's so he gets 2 pepsi's and then he jumps to j so he gets 1 OJ. Both the sets using the 0s and the sets using the 1s express the exact same information and thus the number of combinations sets using 1s equals the number of sets using 0s i.e. C(10,3) = C(10,7).
So every time you get a question like this you can use C(s+c-1,c-1) or C(s+c-1,s) (or if you're a lazy bastard use your programmable calculator to define something like Cr(c,s)). Pick whichever one feels more intuitive to you (the former is more intuitive for me). You don't need to worry about the difference in computational difficulty because
10! = 10!
(10-3)!*3! 7!*3!
is exactly the same as
10! = 10!
(10-7)!*7! 3!*7!
which is the whole reason why the symmetrical rule of combinations exists in the first place!
Another way in which these kinds of problems pop up is where you're told that x,y and z are non-negative integers and you want to know the number of solutions to the equation x+y+z = 12. The vending machine problem could have been expressed like this i.e. if water = w and coke = k (I don't want to make things confusing by calling coke 'c') and pepsi = p and OJ = o then you could say w+k+p+o = 7. So here the number of terms is our 'c' and the number on the right is our 's' so for x+y+z = 12 the number of solutions will be C(12+3-1,3-1) = 91.
What happens if the numbers can be negative? Well then there'd be an infinite number of solutions e.g. the equation x+y=1 has an infinite number of solutions because you can just keep subtracting 1 from and adding 1 to y and the equation will still hold true.
Alright well what if the equation came with some constraints like x+y+z = 12 and x and y are ≥0 by z is ≥-5? We can just bring the problem back to all numbers being non-negative by simply adding 5 to both sides of the equation by first saying v = z+5 so v ≥ 0 and secondly adding 5 to 12 = 17 so we end up with x+y+v = 17 and we can solve the problem normally just by going C(17+3-1,3-1) = C(19,2) = 171 solutions.
This works for both positive or negative numbers: if you were told in the above problem that y≥2 you could just say m=y-2 and turn the 12 on the right hand side into a 10 so that each variable had the condition of being ≥0. You don't need to go and write out the substitutions, you can just crunch the numbers in your head i.e. x≥4, y≥-3, z≥7 and x+y+z = 10 then 10-4+3-7 = 2 so the answer is C(2+3-1,3-1) = C(4,2) = 6.
We can apply the above logic to a similar vending machine problem where our guy is told he needs to get at least 1 of each drink. This is the same as an equation w+k+p+o = 7 where w,k,p,o ≥ 1. Easy fix, just subtract out the 1's from the 7 leaving you with 7-4 = 3 which leads you to C(3+4-1,4-1) = C(6,3) = 20. The intuition behind this is just that if you know he's going to walk away with 1 coke, pepsi, water and OJ then the only room for combinations is in the three remaining slots so the 4 drinks you know he's going to get don't matter at all hence you consider the number of slots to be 7-4 = 3.
Next up may as well do some more stuff involving bitstrings so we'll look in depth at binary numbers.