Prim's Algorithm:
This was the algorithm used by AT&T and other notable telecommunications companies for years, as telecommunication companies often need to find the shortest path for transferring information from one point to another. The algorithm goes vertex by vertex.



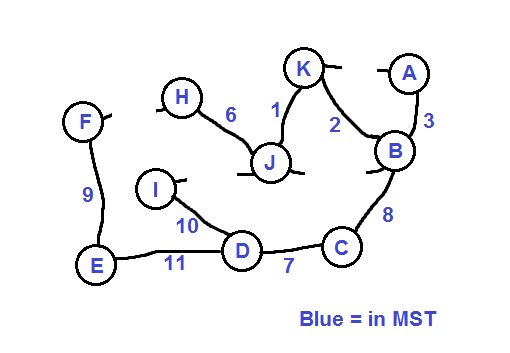
Speaking of which the next cheapest edge connecting to an unvisited adjacent vertex is edge {K,J} so we add that and J. Then we can add H and {J,H}, then C and {B,C}, then D and {C,D}.



So here's the general algorithm in words:
Pick some vertex and add it to the MST
While not all vertices are in the MST:
Add the unvisited vertex of minimum distance to the MST and the corresponding edge
return the MST
Too easy.
Now let's look at Kruskal's Algorithm:
With Prim's Algorithm, we started a tree and grew it, adding the optimal edge with each iteration which didn't connect two vertices already in the tree (i.e. we ensured never to make a cycle). With Kruskal's Algorithm, we create a forest i.e. several trees which all grow and eventually merge together to make the MST. Instead of looking for the next cheapest edge adjacent to our partial MST, we simply go for the cheapest edge regardless of where it is in the graph, and this obviously can create more than one tree at the initial stages of the algorithm. Just like in Prim's algorithm, it is important to not make any cycles (as then it wouldn't be a tree). But unlike Prim's algorithm it's not as easy to know whether you'll be making a cycle because in Prim's you could just check whether the two vertices incident to the edge where already both in the MST and if so adding an edge would be redundant. In Kruskal's Algorithm you may need to link two forests together meaning you'll need to link two vertices already in the MST which means you'll need a means of knowing whether they're in the same cluster or not.



While not all vertices are in the MST:
if the cheapest edge not in the MST will not produce a cycle via its addition:
add the edge to the MST
return the MST
I've given some wordy explanations of why certain things work about these algorithms but here I want to get into more of a formal approach to proving that both of these algorithms indeed are 'correct' i.e. they do indeed produce minimum spanning trees.
I'll start by defining a 'cut'. Recalling that the set of vertices in our graph is V, a cut is a partition of V into two non-empty sets, meaning you decide for each vertex whether it's in group A or B, and you call the cut (A,B). You can refer to the cut as the boundary between the two groups or the two groups themselves; whatever suits your needs. Each edge will either be linking two vertices in A, two vertices in B or a vertex from each group. The edges which interact with both groups are said to 'cross the cut'.

We'll do Prim's Algorithm first and before we prove that it produces a minimum spanning tree we must prove that it produces a spanning tree.
We'll start with the simple lemma (a lemma is a stepping stone towards a proof) that if a graph is disconnected, you can make a cut which has no edges crossing it, and vice versa. By definition a graph is connected if there is a path from every vertex to every other vertex. This is called the empty-cut lemma.
We can select two vertices u and v, and assuming there is no path from u to v (the graph is disconnected), it's easy to show that you can make a cut between the two vertices and have no edges crossing it (i.e. an empty cut), by defining A as all reachable vertices from u and B as all reachable vertices from v and then acknowledging you've got two non-empty sets (a cut) for which no edges cross. Going the other way, we can assume there is a cut between u and v for which no edges cross and it's clear that there cannot be a path from u to v because such a path requires an edge to cross the cut. I am aware of how blatantly obvious this lemma is but we must play by the mathematical proof-making rules if we are to create a rigorous proof.
So now we've got a way of talking about connectedness in terms of whether you can make an empty cut from the graph.
Second lemma: the double crossing lemma:
This one states that if you have a cut and you have a cycle which includes vertices in A and B, then there must be more than one edge crossing the cut participating in that cycle. The reason is that a cycle is a path that begins and ends at the same vertex, without re-using edges. This means that if your cycle begins in A and goes to B, it must come back via another edge and vice versa if you consider it to start in B. This lemma is actually a weaker version of saying that there will be an even number of edges crossing the cut because each time you cross the cut, you need to cross back again.
This leads us to the Lonely Cut Corollary (a corollary is a proposition which follows from something already proven), which states that if there is only one edge crossing a cut, it is not part of a cycle.
Alright so we've set up the two basic lemmas that we need, now let's consider a bit of terminology. The set of vertices which our algorithm has added to the MST is X and the set of edges is T. This means the vertices not yet added are in the set V-X. If a set of edges 'spans' a set of vertices then the graph produced from the edges and vertices is connected (no empty cuts).
1) T always spans X. This is because the algorithm always adds one vertex at a time and when it does, it connects that vertex to the MST via an edge, so considering the algorithm never leaves the MST to go and start a new tree (like in Kruskal's Algorithm), we'll always have a connected graph.
2) When the algorithm's done, X = V. This is because for us to not have all the vertices in X by the end, then at some point we'd have an empty cut (X,V-X) and if that's the case then our graph is disconnected and we only take connected graphs as input. Combining 1 and 2 tells us that by the end we'll have a connected graph containing all the vertices.
3) No cycles ever get created in T. This is because at each point in the algorithm you're adding an edge that crosses the cut (X,V-X) and in doing so, you grow X by one vertex and shrink V-X by one vertex. This means that next time you're going to be doing exactly the same thing with the new cut (X,V-X). As we stated in the double-cross lemma, a cycle requires two edges crossing the same cut so in order to create a cycle you would need to add the edge to your MST without changing the two vertex sets; thus we always get a lonely cut and never create a cycle.
Pictorially let's look at why cycles don't get made:



So there's our long-winded proof that Prim's Algorithm indeed makes a spanning tree. Speaking of trees this reminds me of the scene in Lord of the Rings where Treebeard tells the two hobbits after a very long discussion with fellow trees (okay they're actually 'ents' for the lotr fans) that they've all decided the hobbits aren't orcs. Nonetheless let's power on to finding out why the algorithm gives us a minimum spanning tree.
So the first thing we need to do is prove the 'cut property' which states that if you have a cut (A,B) and of the edges crossing it, e is the cheapest, then e will be in the MST. We'll do this by contradiction: assuming we have an optimal solution, then exchanging an edge for e to get a better solution, which contradicts the assumption that our original solution was optimal.
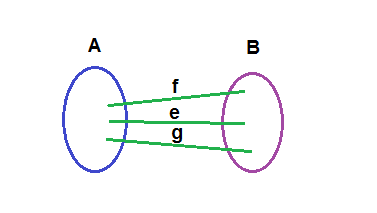
So let's say in the MST which we'll call T* we have a cut (A,B) and although e is the cheapest edge crossing that cut, we instead have f in T*, which is more expensive. Obviously we need some edge or otherwise we'd end up with a disconnected output which wouldn't be a spanning tree (based on the empty cut lemma).

Not only this, but if we exchanged f for e we'd leave a vertex disconnected in B. This tells us that we can't just swap any two edges and hope to be left with a MST. Having said that, it is always possible to exchange e with some edge, which in this case is g. If we took g out and put e in, meaning we'd have e and f crossing the cut, we wouldn't have any cycles or disconnects and as e is the cheapest edge crossing the cut we would have reduced the total weight, thus contradicting the assumption that T* was an MST.
Observe that when you have a spanning tree, adding any extra edge will produce a cycle because if the endpoints of the added edge are u and v, then as they already had a path from one to the other (which is part of the definition of a tree: each vertex has a path to every other vertex) the new path given by the edge will produce a cycle (as two separate paths from u to v create a cycle). So if we add e to our spanning tree, we know a cycle will be made. Using the double edge lemma we know that a cycle which crosses a cut at least once must cut it twice, meaning there will be another edge (in this case g) which we can remove to break the cycle. In doing so we will certainly reduce the total weight of the spanning tree because we knew at the beginning that e was the cheapest edge crossing the cut.
Now we need to consider the chance of any disconnects after exchanging the two edges. Because the vertices in the cycle had two paths between them, after removing g and thus breaking the cycle, there will still be one path between them, meaning we don't lose any connectivity in the spanning tree.
So if we have a T* for which such an exchange is possible, then T* is not a minimum spanning tree, and if no such exchanges are possible, it is a minimum spanning tree. This gives us the cut property where for any cut in a graph, the cheapest crossing edge will be included in the MST. As Prim's Algorithm always chooses the cheapest edge crossing the cut (X,V-X) (where X=A and V-X = B in the above exchange approach) due to utilising the cut property, it will end up without any opportunities for such an exchange meaning that it indeed produces a minimum spanning tree.
Now onto Kruskal's Algorithm. Again we need to prove it indeed produces a spanning tree i.e. it has no cycles and no disconnects. Again, we'll say T is the set of edges produced by the algorithm at any point in that algorithm's runtime.
The cycles part of this proof is easy because Kruskal's algorithm specifically prohibits the adding of any edges which will produce a cycle, so this is self-evident.
The connectedness part is a little bit more tricky. We can use the definition of connectedness that for any cut (A,B) in our graph G, there must be an edge crossing it in the MST. Assuming Kruskal's Algorithm considers all edges at one point, and that our input graph G was connected (and thus has at least one edge across every cut) all we need to say is that via the lonely cut corollary the algorithm will have no problem adding an edge across any given cut to T when previously there were no such edges in T because doing so won't create a cycle, as a cycle which crosses a cut requires two edges to cross it. So as each cut in our output will have at least one edge crossing it, we know the output is connected.
This is assuming we consider each edge which isn't true, as we can stop as soon as we have added all the vertices. We'll know we've added all the n vertices when we've added n - 1 edges. Why? Consider a tree and you pick a random vertex. Then to reach the other vertices you need one edge each hence you end up with n - 1 edges. If you have n - 1 edges and no cycles (which this algorithm will give you) then you necessarily have a spanning tree.

As for Kruskal's Algorithm producing a minimum spanning tree, it's not as simple as it was with Prim's. With Prim's the pseudocode explicitly appeals to the cut property where you add the cheapest edge crossing the cut (X,V-X), but here the algorithm is just adding the cheapest edge which doesn't create a cycle. We need to show that the algorithm inadvertently appeals to the cut property.
So let's say we're going to add an edge e which links u and v. Obviously u and v will be in different clusters or otherwise there would already be a path between them and by adding the edge we'd be producing a new path and hence a cycle. This means we can manufacture a cut between the two clusters for which our edge crosses. As for the other clusters, whether they're in A or B is irrelevant. The fact that the algorithm is considering e before any of the grey edges means that it is the cheapest. The fact that e is the cheapest edge not yet added to T means it must be the cheapest edge crossing the cut and by the cut property, the cheapest edge across any cut belongs in the MST. The only reason the Kruskal's Algorithm has to not include the edge is if it creates a cycle which is impossible because the cut was empty at the beginning of the current iteration of the algorithm and adding an edge across it cannot possibly form a cycle by the lonely cut corollary.

I'll leave the post there because it's gotten quite long, and next post I'll talk about faster implementation methods such as heaps in Prim's Algorithm and the Union-Find data structure in Kruskal's Algorithm.
Special thanks to the youtube channel YogiBearian for great explanations on minimum spanning trees.
No comments:
Post a Comment